
How to distinguish between two kinds of 7s?
There are two acceptable ways to write the digit ‘7’. It can be written with or without a line in the middle. Given an unlabelled dataset of 7s written in both ways, the task is to find which ones have a dash and which ones don’t.
| Without Line | With Line |
|---|---|
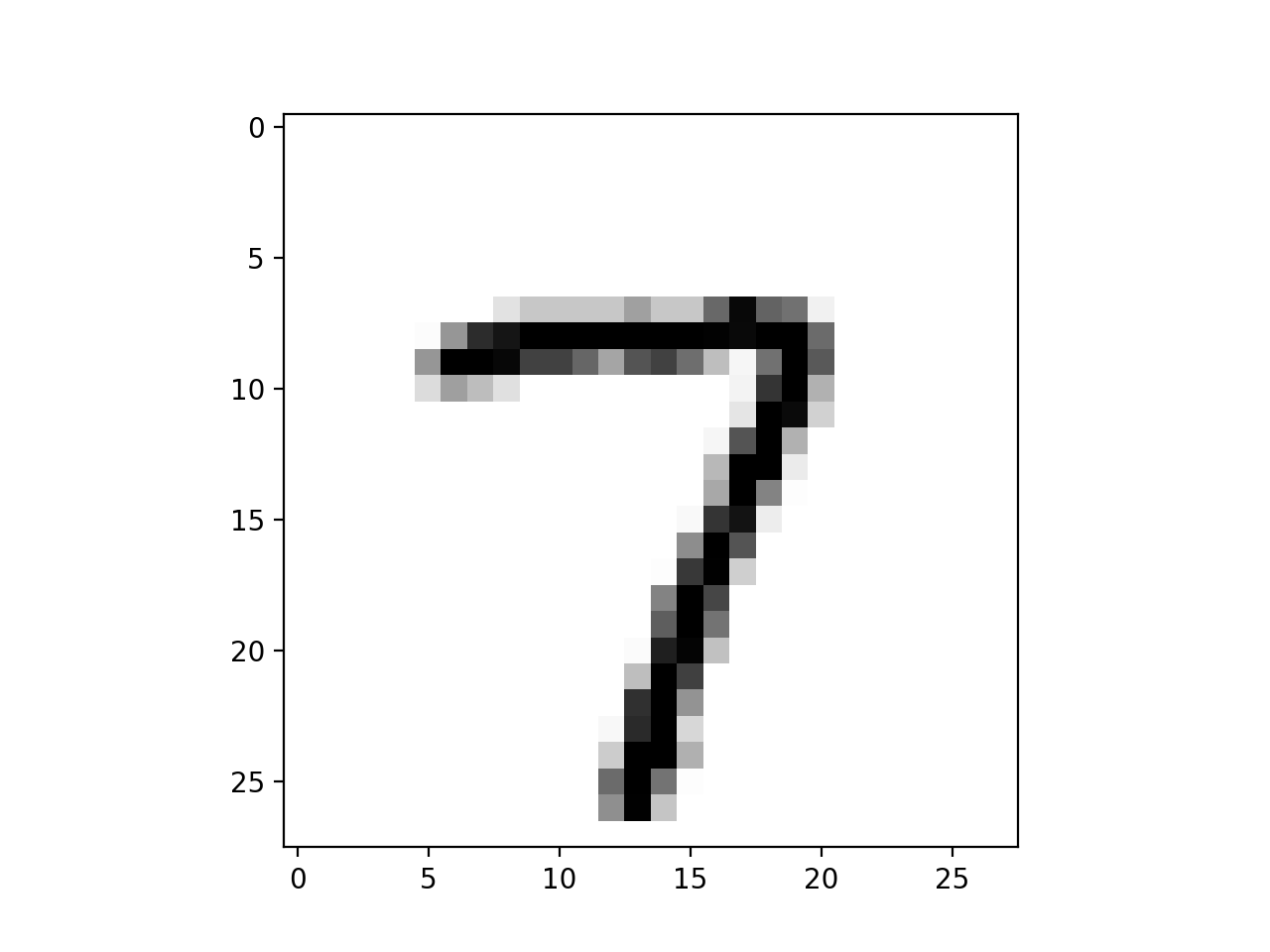 |
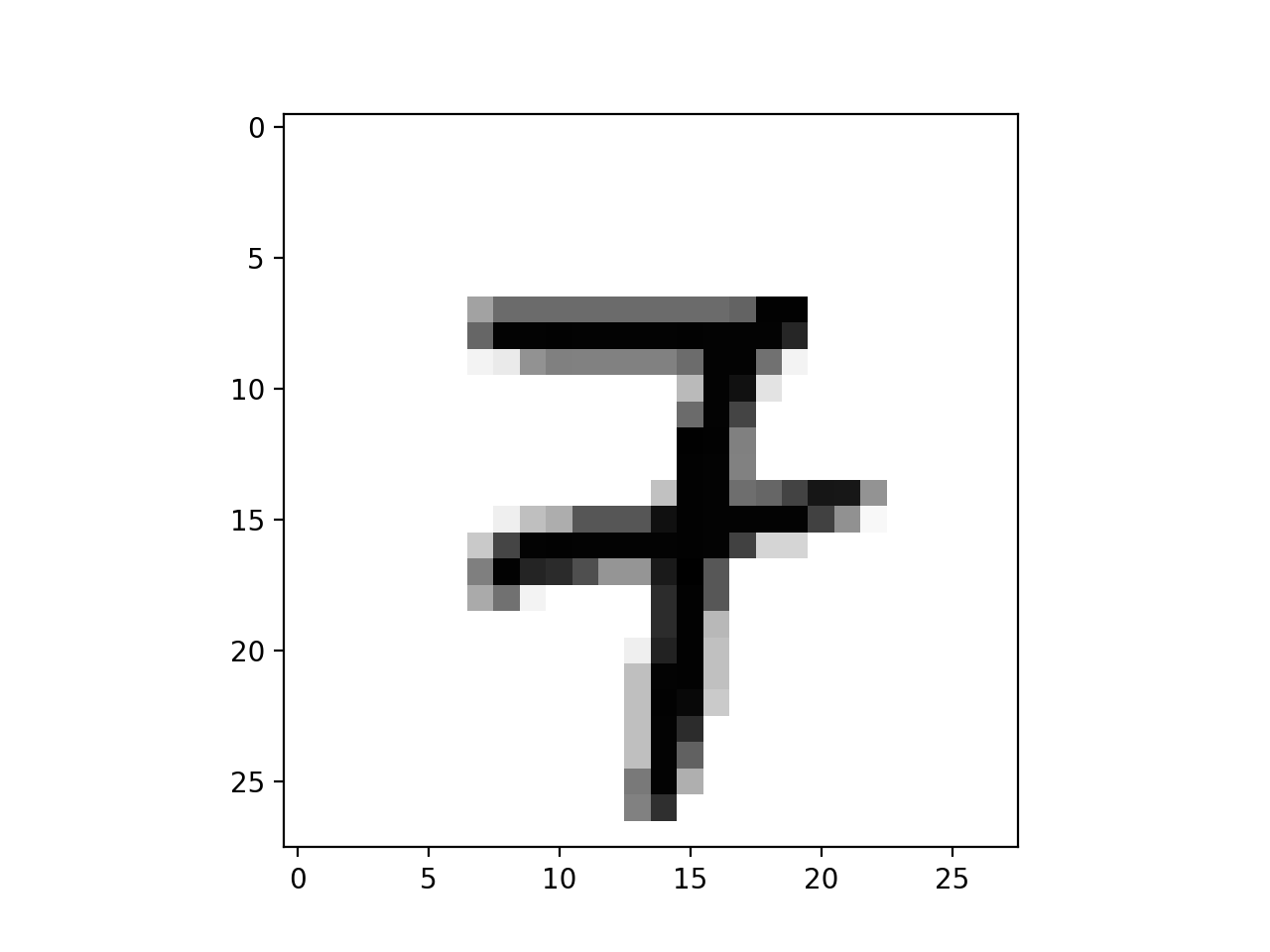 |
This was a tiny part of my final project for the graduate ML (689) course at UMass. It was joint work with my fellow graduate students Subendhu Rongali and Emily First. I will briefly talks about the project itself at the end of the blog. For now the problem is to just to find which kind of 7 is in the picture.
I encourage you to think about how you might accomplish this using unsupervised machine learning or image processing before reading our solution below.
We came up with this easy and intuitive solution to this problem:
- Sum up the pixel densities horizontally to get a 1-d pixel density curve.
- Count the number of peaks in it.
Here is our solution in images
1.
| Without Line | With Line |
|---|---|
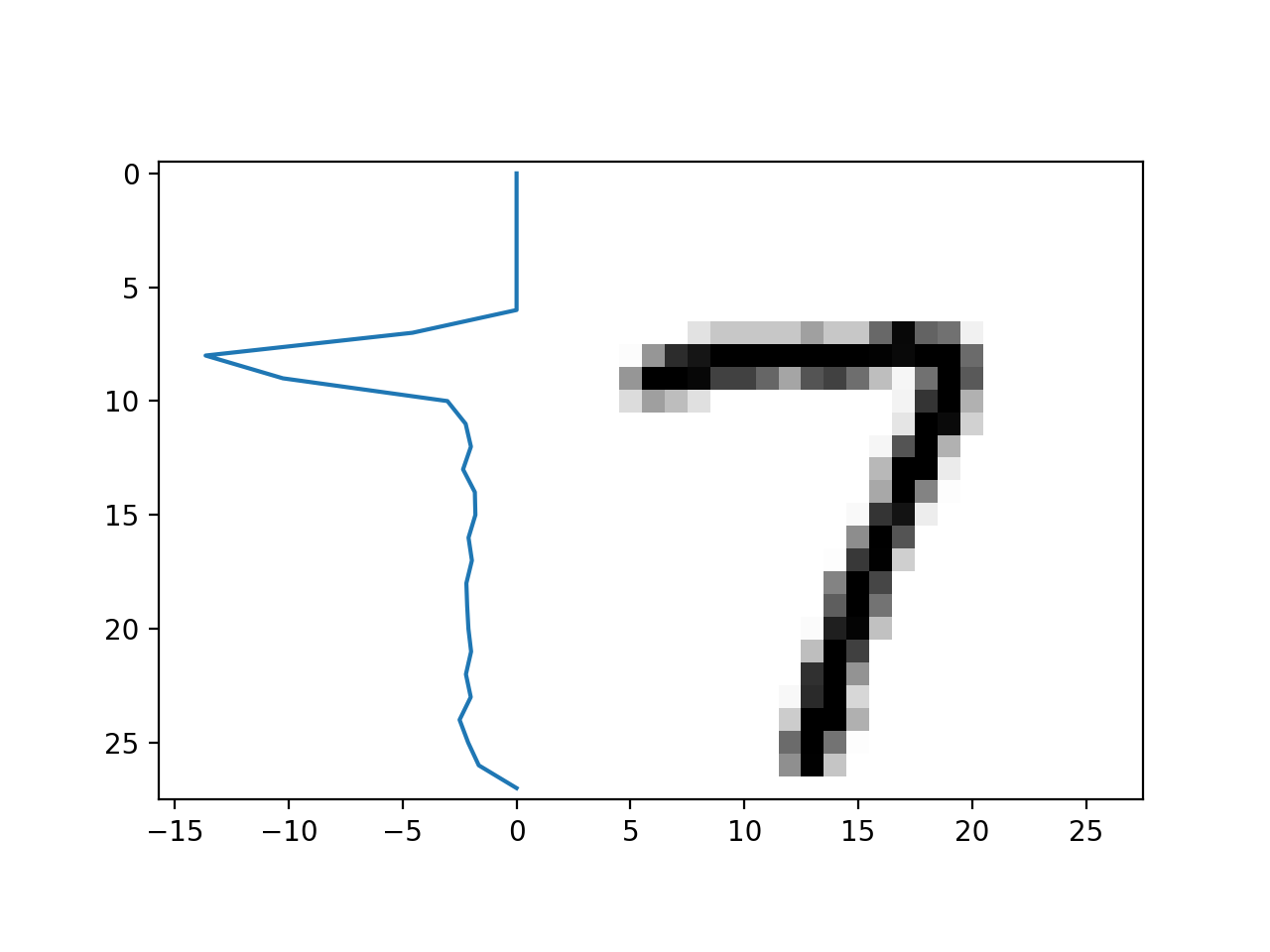 |
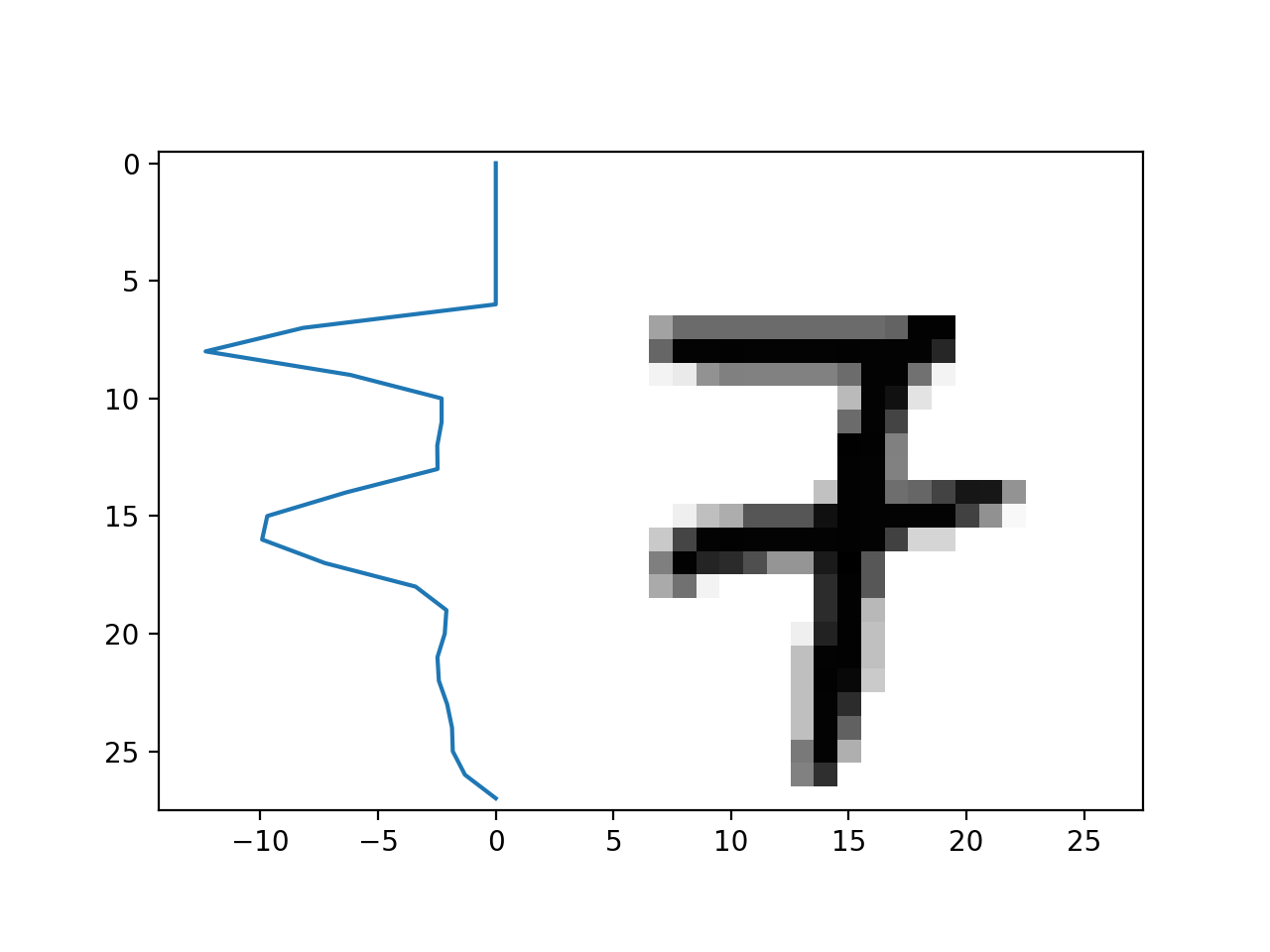 |
2.
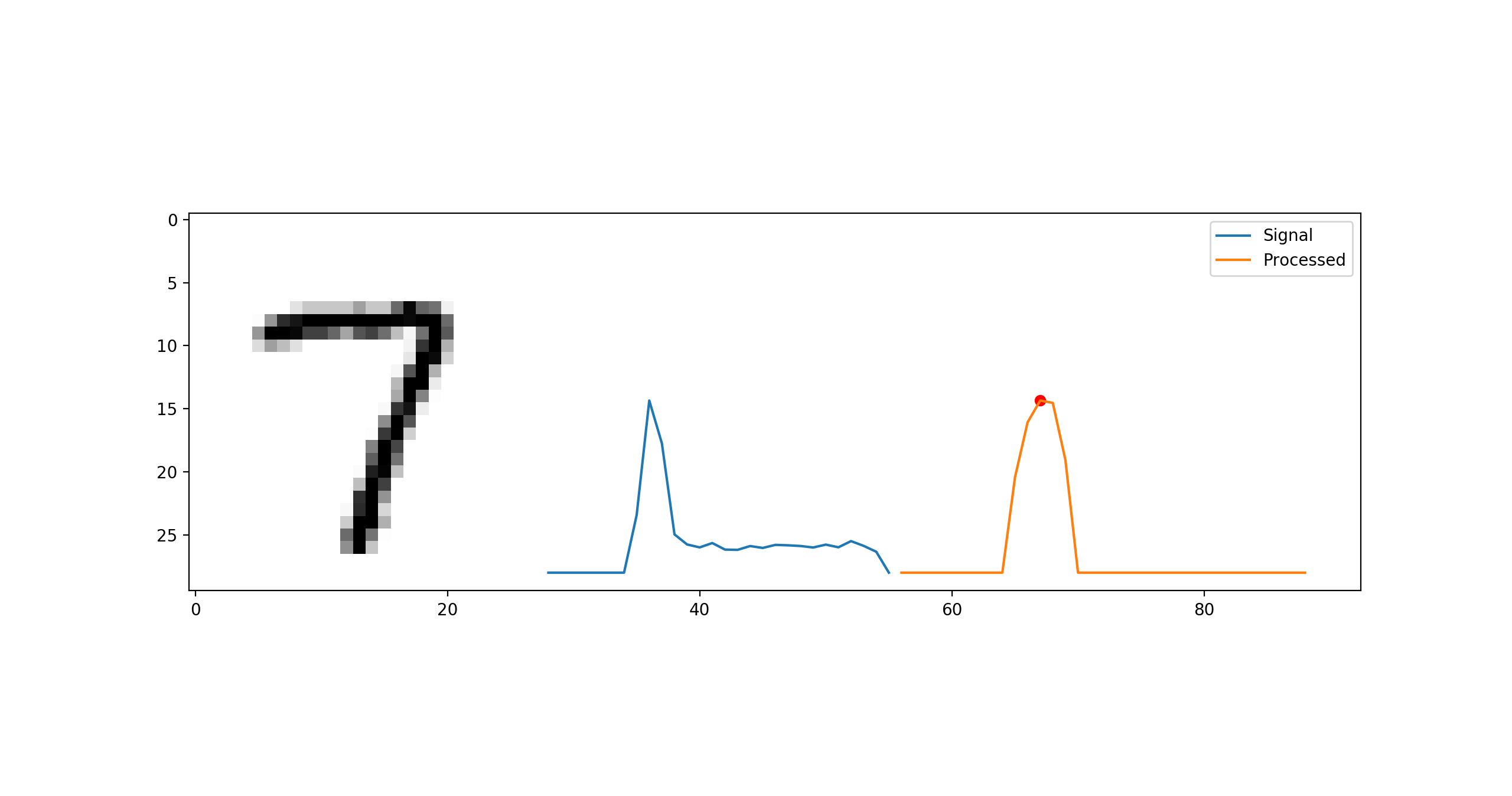
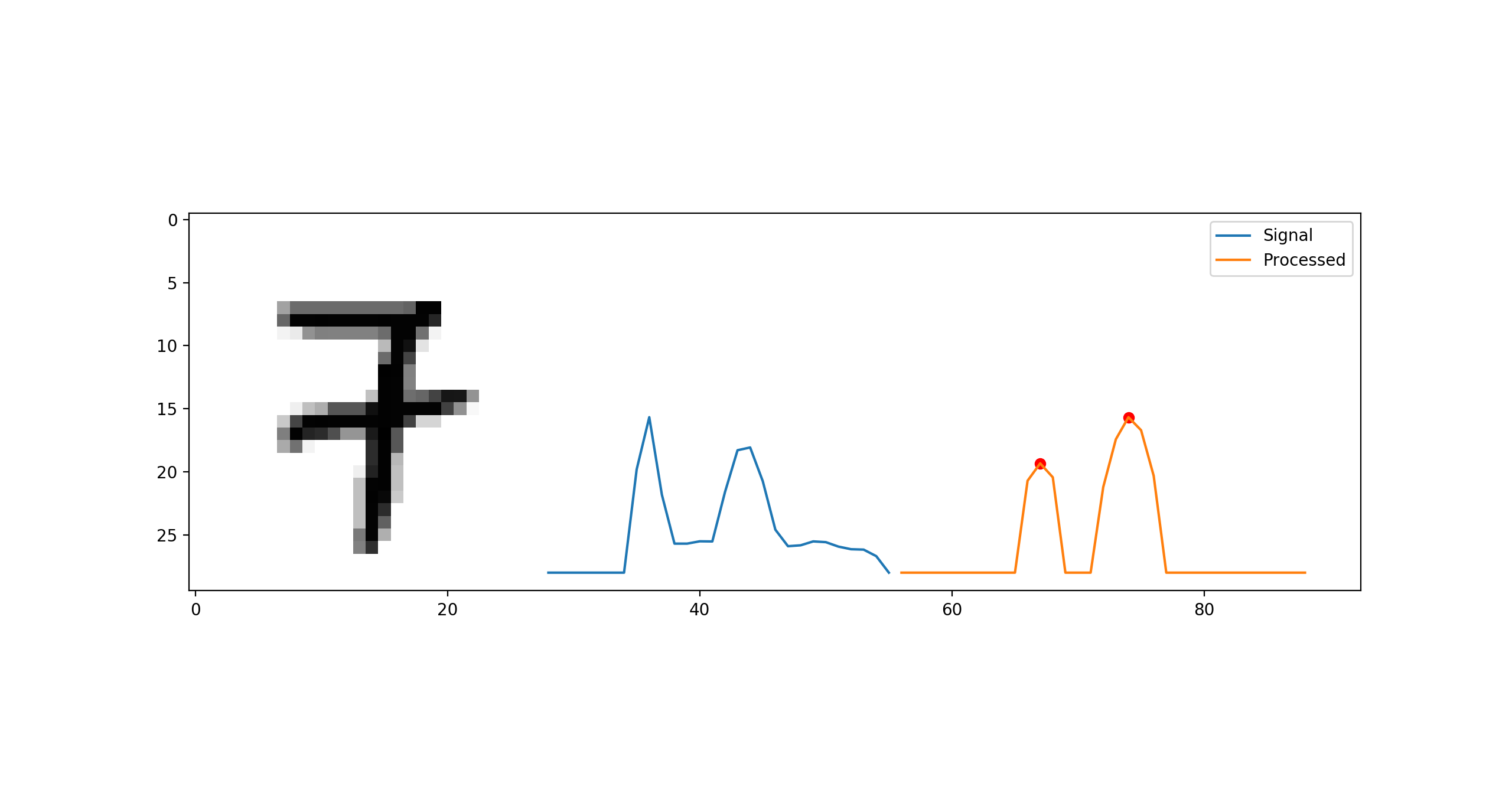
To find the number of peaks, we simply convolve the 1-d signal with a gaussian filter, remove noise by thresholding at half of the maximum and count the number of relative maxima using scipy.signal.argrelmax
This simple signal processing heuristic works very well in practise. Out of the 5715 images of 7s in MNIST our technique said 654 images are 7s with lines. Although we could not manually check to see how bad we did, we were pretty satisfied with this heuristic as it gave very good results in the experiments for our project.
In our project, we wanted to use Influence Functions to understand how a sub-population of data points effect model predictions. According to wikipedia:
The line through the middle of 7 is useful to clearly differentiate the character from the number one, as these can appear similar when written in certain styles of handwriting.
We used influence functions to validate this. We train a simple logistic regression model for classifying 1s and 7s. We found that the population of dashed 7s have a huge positive influence score in making the right predictions. When we removed this population from the training set and retrained the model, we observed that there was a significant drop in accuracy. The population of dashed 7s indeed helps the model in distinguish between 7s and 1s.